Across the health care ecosystem, payers, providers, pharmacy, and life sciences organizations are leveraging data lakes, seeking to unite disparate structured and unstructured data from multiple sources such as claims data, clinical data, social determinants of health, and quality insights to name a few. But what exactly are we talking about when we talk about a data lake?
What is a health care data lake?
The concept of “big data” was coined well more than a decade ago and has gained momentum as the sheer amount of data collected across all sectors began its exponential growth. How do big data and data lake intersect? And is a data lake the same as a data warehouse? James Dixon, the CTO of Pentaho who is credited with the naming of the concept of data lake, described the concept of a data lake to Forbes: “If you think of a data mart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.”
In short, a data lake serves as a centralized repository where both structured and unstructured data is stored at any scale. The health care industry has a rich amount of disparate patient data that needs to be structured and streamlined to help physicians, health care organizations, payers, and scientific researchers make informed, data-driven decisions. A cloud-based health care data lake solution enables the combining of complex and disparate data, delivering insightful analytics to solve complex business and clinical issues.
According to a white paper from Scalable Health, the benefits and potential impact of a healthcare data lake include a comprehensive view of patient care, the ability to process huge data volumes at once, enhanced query processing, lower costs, and a faster time to greater insights.
A data lake serves as a solution for companies that have large amounts of data pocketed in different places and are managed by different groups. Having a centralized repository of data prevents the data from being obscured. Since there are no predefined schemas for the data imported into data lakes, users can ingest data in real time. And with the right governance, data lake administrators don’t have to worry about managing access for multiple databases because data lakes have security controls in place that grant authorized users access to see, process, or modify a specific asset, while keeping unauthorized users out and preventing confidential data from being compromised.
How does a data lake differ from a data warehouse?
In contrast to a data lake, a data warehouse stores data in an organized, structured manner with everything archived and ordered in a defined way, similarly to a computer drive where there’s a folder for pictures, videos, documents, and downloaded content, and every file or media content has a designated folder on the drive. The concept is the same for a data warehouse. Unlike a data lake, a data warehouse takes more time to develop, requiring a significant amount of effort in the initial developmental stages as each data source needs to be analyzed and the business use clearly defined before the data is loaded into the warehouse. On the other hand, a data lake is centralized, meaning everything is stored in one big repository rather than stored as individual files like the data in a data warehouse. In a data lake, both structured and unstructured data can be stored at any scale, meaning the data being inputted into the data lake doesn’t have to be analyzed or evaluated for future business use.
A typical data lake would contain multiple sources of data that could be contained in a single integration layer or by integrating multiple channels through an API connected to the enterprise data lake. Many such sources are claims and enrollment data, quality and risk insights, genomic health, linked external datasets, data coming from ACOs and health systems, national registries, and analytics coming from client and vendor entities.
A 2017 Aberdeen survey found that organizations that implemented a data lake were more likely to outperform their competitors by 9 percent in organic growth. An effective health care data lake solution provides a single source of truth for data that supports advanced reporting, analytics initiatives, and other use cases. It’s this ability to transform the structured and unstructured components of the data lake into a data mart that can be configured with the latest technologies to quickly support numerous business use cases and consumption models that underscores the power of getting the foundation right.
Another key benefit of adopting a data lake is that it makes it easier for organizations to train and deploy more accurate machine learning and artificial intelligence (AI) models. AI and machine learning technology, including Python, thrives on large, diverse datasets, and a data lake serves as a powerful foundation to support the training of new algorithms for these technologies.
For a further detailed explanation on the key benefits of data lake and how it differs from a data warehouse, review the table below, originally published by Amazon:
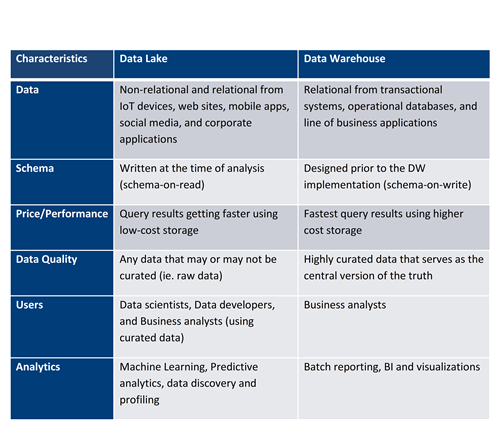
By housing a data lake, health care enterprises have the power to not only accommodate disparate data sets but also craft strategic tools, like analytics and insight sharing with payers and providers through a well-configured data mart. Looking into the future, health systems and enterprises have tremendous potential to remain highly cost effective while also reliably processing large chunks of data in real time, accelerating query processing and building a population health management model on its own accord.
Avoiding the data swamp: How to maintain a healthy data lake
While one of the greatest appeals of a data lake is its ability to accept unstructured data and break down silos, the tradeoff of is having large amounts of data that is of no value to its users because the data lake has become a swamp, and users are unable to access the information they need. With no constraints on where data in a data lake originates and no regulation on what is done with that data once it is ingested into the data lake, how can you ensure that quality data is being ingested into the repository?
Metadata tags: Organizations should consider the use of metadata tagging to add some level of organization to what’s ingested to make it easier for data lake users to find relevant data queries and analysis.
Catalog: Providing a catalog that makes data visible and accessible to all data lake stakeholders can mitigate future challenges with the data lake.
Parameters: To avoid your data lake from transforming into a data swamp, detailed parameters should be set regarding the kind of data and how much data resides in the lake.
Data governance: Establishing data governance – who handles the data, where the data resides, and how long the data is retained – is vital to the success of a data lake. This concept of data provenance will continue to grow as more disparate data sets are merged, de-duplicated and consumed for downstream activities, and it’s especially critical when treatment decisions are made on such data insights.
Data lake: Here to stay
There is a great deal of buzz around data lake, especially in the health care industry. But given the complexity of technological requirements and architecture necessary to support a data lake, organizations are taking their time to complete the appropriate due diligence.
For the companies that are interested in developing a data lake solution, the first step is to adopt the necessary data architectures. This means leveraging the cloud for data lake architectures, which entails a financial investment to build a data repository. While this tends to be a large undertaking and a financial investment for most organizations, the ROI is worth it in the long term.
Data lakes will continue to add value to organizations by breaking down data silos and empowering users with actionable insights to allow them to make data-driven, clinical, and quality decisions that contribute to measurable impact for members and the economic performance of the health plan.
About the author

 Eric Sullivan serves as senior vice president of innovation and data strategies at Inovalon, supporting the innovation towards new product and technology solutions and providing executive leadership over all data integration, management, and governance programs as well as the MORE2 Registry® data asset.
Eric Sullivan serves as senior vice president of innovation and data strategies at Inovalon, supporting the innovation towards new product and technology solutions and providing executive leadership over all data integration, management, and governance programs as well as the MORE2 Registry® data asset.
For more than 25 years, Sullivan has been leading clinical innovation and data-driven solutions in a variety of roles in the health care sector—with a keen focus on developing data-driven models to transform health care by improving quality, outcomes, and efficiency. He has held leadership positions in some of the nation’s largest health plans including UnitedHealthcare and led teams in the clinical care setting to deliver patient-centered, patient specific health care. His current role advances patient-precision analytics by leveraging big data technologies, Natural Language Processing (NLP), interoperability and real-time clinical data patient profiling.
Sullivan received his M.S. in Health Care Administration as well as an M.B.A from the University of Maryland. He also holds a B.S. in Neurobiology from the University of Maryland College Park.